System status monitoring
Overview
System health monitoring allows you to assess whether the system has indications for administrator intervention to address risks that have arisen.
Builds on polling /system/state and possibly executing other design scenarios to monitor the states of important entities.
The main function of monitoring is timely notification. It works proactively and is indicated for use on all system instances. The administrator’s job is to keep the system in a normal state and to react to the appearance of the monitoring issue
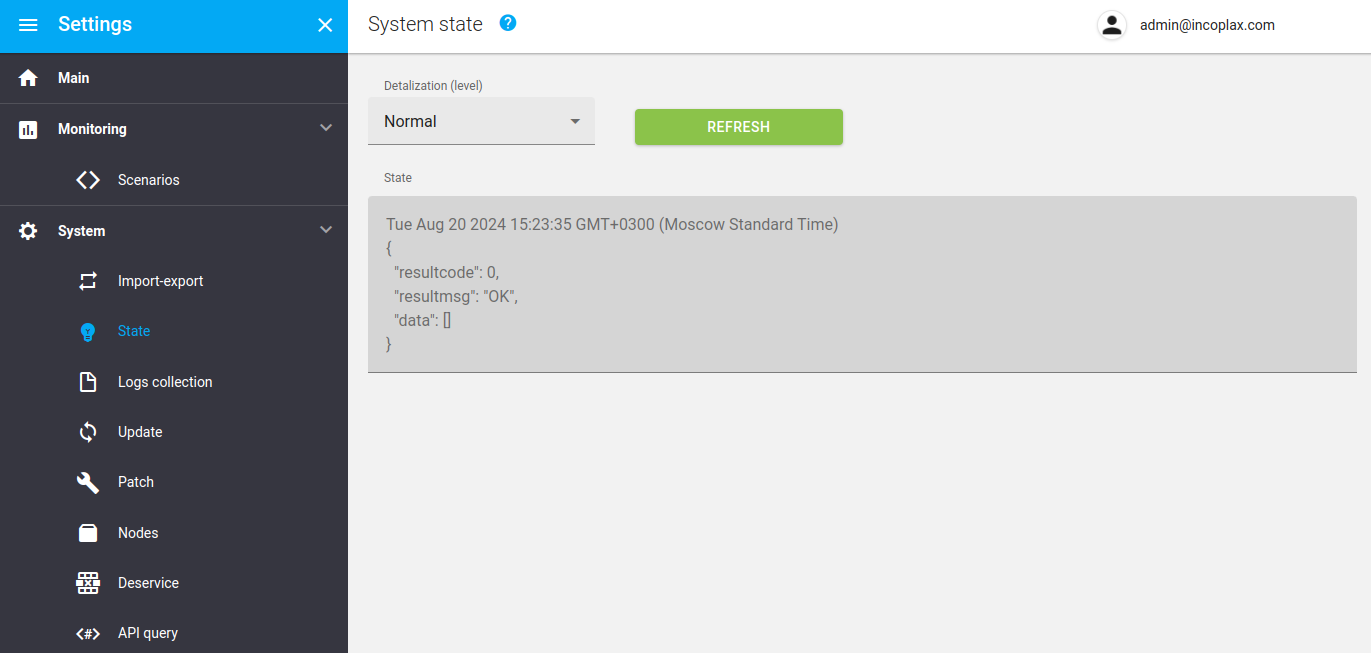
Manual status polling
May be carried out:
-
after technical work has been carried out to ensure that the system has returned to normal.
-
when unexpected and unplanned symptoms occur.
Conducted from the app or via API:
Customizing the notification
Setting up regular notification of changes in the system state allows you to timely inform responsible administrators about suspicious events interpreted as deviations from the normal process.
-
SNMP-gangways. Notify not only health-check, but are also able to inform about other types of events.
-
Telegram-bot. Allows you to be online at all times, receive notifications of /system/state changes, poll /system/state from your mobile device from anywhere in any environment.
-
Service task and scripts, querying the /system/state. Allow any health-check logic to be implemented, not limited by execution time, but limited by execution within the cluster.
-
External processes that regularly query the system APIs, including /system/state and execute any preconfigured scripts. Independent of the non-failed state of the cluster.
The algorithm for finding out the state of /system/state can be configured in the master domain: parameter system_state_options.